Eating Your Own Dog Food: Building the Extraction API for Cently (and Everyone Else)
December 18, 2025
When you upload a receipt to Cently, something interesting happens behind the scenes.
Your photo doesn't just get thrown at an OCR API. It goes through a pipeline. First, we straighten it (because phone photos are rarely perfect). Then we read the text. Then we organize the data. Then we save it back to you.
Each step happens on its own specialized service, running on Cloudflare. And it's reliable enough that we've actually opened it up for other people to use.
The problem: receipts are chaos
Text recognition works great on clean documents. But receipts? Receipts are taken with phone cameras by people in bad lighting, at awkward angles, sometimes with glare on the screen.
Standard OCR fails constantly. You get words backwards. Numbers cut off. The total shows up in the wrong place. Line items vanish.
But there's an even bigger problem: even if OCR works perfectly, the data you get back is just text soup. "STARBUCKS #1234 DOWNTOWN" - great, but where does that go in the receipt? Is it the merchant? Is it an item?
This requires specialized APIs for specialized jobs.
What we built: extraction-api on Cloudflare
We realized we were solving these receipt problems in Cently, but other companies needed the same solutions. So we built dedicated APIs:
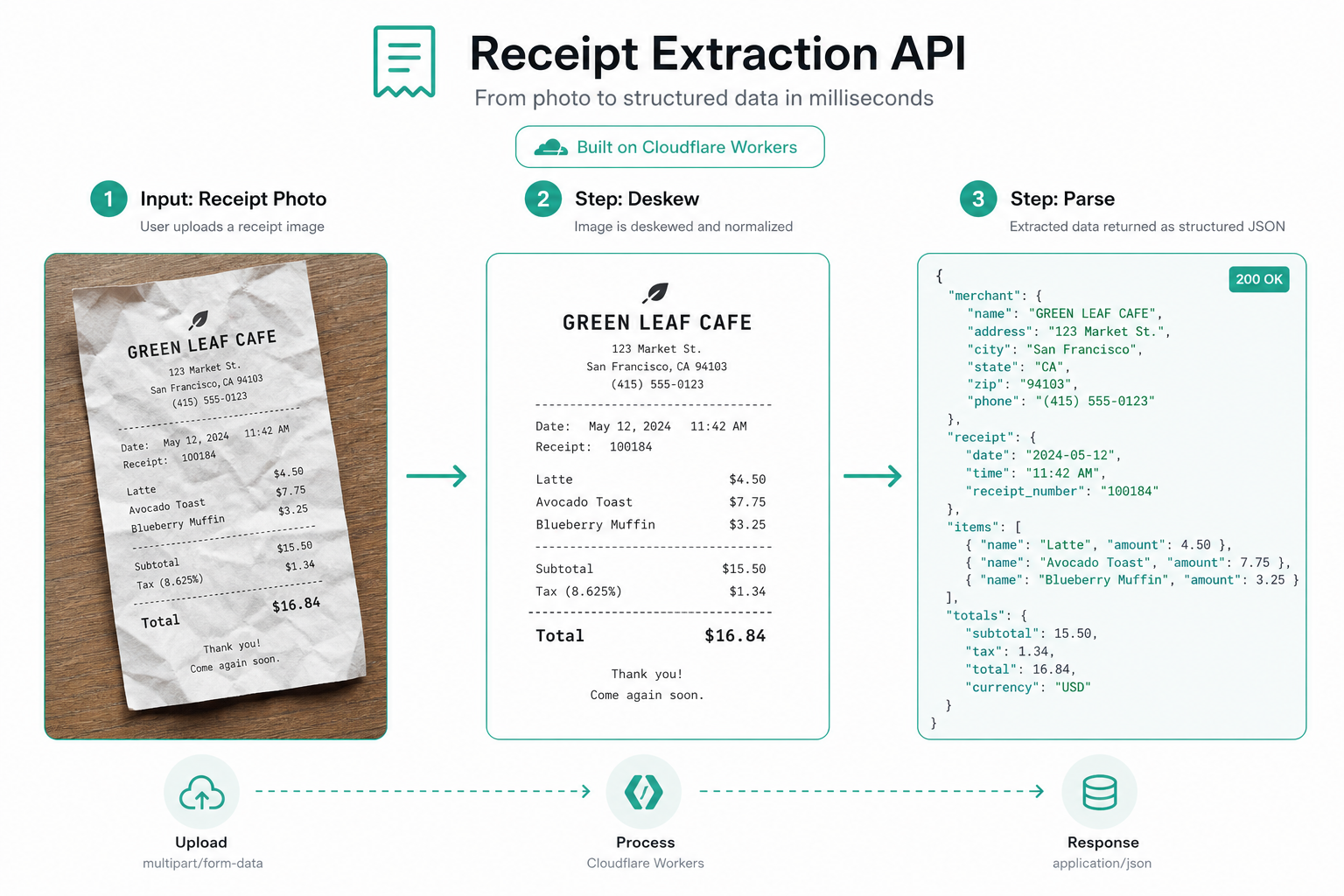
/v1/deskew - Takes any image (receipt, invoice, document, whatever) and straightens it. Removes tilt. Removes perspective distortion. Returns a cleaned-up image ready for OCR.
/v1/parse - Takes the straightened image (or any image) and extracts structured data. Line items. Totals. Merchant name. Tax. Tip. Date. All parsed and organized.
Both run on Cloudflare's infrastructure. Both are available to authenticated users who have an API key.
How Cently uses its own API
Here's the interesting part: Cently uses these APIs on itself.
When you upload a receipt to Cently, we:
- Send the image to
/v1/deskewto straighten it - Send the straightened image to
/v1/parseto extract the structured data - Merge the parsed data with your transactions
But because these are actual APIs on actual infrastructure, you can use them too. It's not closed-source magic. It's a service.
The architecture that makes this possible
We run these on Cloudflare Workers with Durable Objects. Here's why that matters:
Durable Objects handle the heavy lifting. The deskew processor runs in one container. The receipt parser runs in another. Workers orchestrate the flow, handle authentication, manage billing, and route requests.
Auto-scaling happens automatically. Got 100 receipt uploads? The system scales. Got 10,000? Same deal. You don't manage infrastructure. Cloudflare does.
Billing is metered. For API key users, we charge per usage. For Cently users with active subscriptions, it's unlimited. This means you can iterate and experiment without worrying about surprise bills.
Why this is different from DIY APIs
You could build receipt parsing yourself. But here's what you'd have to figure out:
- How to handle images that are sideways, upside-down, or heavily distorted (the deskew part)
- How to extract meaningful data from OCR text soup (the parse part)
- How to scale this to millions of requests
- How to avoid crashes when someone uploads a 200MB TIFF file
- How to handle PDFs vs JPGs vs PNGs vs HEIC
- How to respect rate limits and prevent abuse
We solved all of that. The API is boring and reliable, which is exactly what you want from infrastructure.
The real use case
Here's why we think this matters:
If you're building a fintech product, an expense management tool, a tax app, or anything that touches receipts, you probably need exactly what we built.
You could spend three months building this. Or you could use the extraction-api and spend that time building the thing that actually matters: your product.
The APIs are simple:
curl -X POST "https://extraction-api.upcaret.com/v1/deskew" \
-H "Authorization: Bearer <API_KEY>" \
-H "Content-Type: application/json" \
-d '{
"fileUrl": "https://example.com/receipt.jpg"
}'
Response tells you exactly what happened:
{
"requestId": "7b4b44b0-34c2-4e65-8b65-6fe7c7d8e1a2",
"imageBase64": "iVBORw0KGgoAAAANS...",
"contentType": "image/png",
"deskewAngle": -2.3
}
Same deal for parsing. Send an image, get back organized data.
The philosophy: eat your own dog food
We built these APIs because Cently needed them. We proved they work by using them ourselves every single day.
Only then did we open them up. This means they're battle-tested. They handle the edge cases. They scale. They're reliable.
When you use extraction-api, you're using the same infrastructure that powers Cently's receipt processing. It's not a side project. It's core infrastructure.
What makes this sustainable
Open APIs are only useful if they're maintained. Here's what we committed to:
- Backwards compatibility. We won't break existing API calls. Ever.
- Performance. Deskew and parse both run in under 2 seconds for most receipts.
- Scale. Whether you process 10 receipts a day or 10,000, the API behaves the same.
- Documentation. Every parameter documented. Every response format explained.
The bigger story
This is what eating your own dog food actually means. You build infrastructure for yourself. You make it really good. You prove it works at scale. Then you open it up.
It's not an afterthought. It's not a "nice to have." It's core.
That's how you build infrastructure that other people actually want to use.
If you're building something that needs reliable receipt processing, deskewing, or OCR, you can stop building it from scratch.